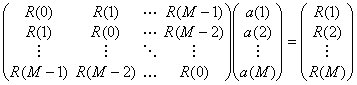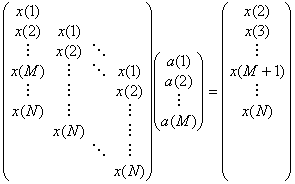今日の例題 「 ARモデルの同定 」
- 解説: AR(自己回帰)モデルによる時系列の予測
時系列 x(s) のARモデルによる予測は,以下の式で与えられる。
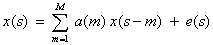
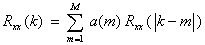
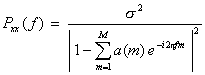
- 例題プログラム: [ ar_model.m ]
次のプログラムでは,3つの正弦波に少し正規白色雑音を加えた時系列を例として,まず,その時系列に対してYule-Walker法によるARモデルの推定を行っている。また,そのスペクトルを求めて,Welch法によるFFTスペクトルと比較している。さらに,そのARモデルによる予測を行って,与えられた時系列と予測した時系列がどれほど良く一致するか比較している。
オリジナルのプログラムは, こちらから,ダウンロード% ar_model.m
%
% < AR_model identification >
%
Fs = 200; T = 1; N = Fs*T;
t = (0:1/Fs:T-1/Fs);
rn = 0.02*randn(size(t));
%
% ----------------------signal---------------------------
x = sin(2*pi*2*t) + sin(2*pi*10*t) + sin(2*pi*25*t) + rn;
% -------------FFT spectrum (Welch's method)-------------
[Pxx,f] = psd(x,256,Fs,hanning(256),128,'none');
% -------------------------------------------------------
%
% AR model estimation
%
M = 4; % order of AR model <---かえてみよう
[a,e] = aryule(x,M); % Yule-Walker method
% e: variance of prediction error
% [a,e] = arburg(x,M); % Burg method
Pxx_ar = e*abs(freqz(1,a,N/2,Fs)).^2; % spectrum (AR model)
f_ar = (0:1/T:Fs/2-1/T);
%
subplot(311);plot(f,10*log10(Pxx),'-b',f_ar,10*log10(Pxx_ar),':r');
legend('Pxx (FFT spectrum)','Pxx (AR spectrum)')
ylabel('Magnitude (dB)'); xlabel('Frequency (Hz)');
%
% prediction by the AR model
%
y = zeros(1,N);
a(1) = [];
for I=M+1:N
for J=1:M
y(I)=y(I)-a(J)*x(I-J);
end
end
% ------------------------------
xest = y(M+1:N);
t(1:M) = [];
x(1:M) = [];
subplot(312);plot(t,x,'-b',t,xest,':r');ylabel('Amplitude')
axis([0,T,-3,3]);legend('x (obserbed)','x (predicted)')
subplot(313);plot(t,x-xest);
axis([0,T,-0.5,0.5]);legend('x-xest')
ylabel('Prediction Error'); xlabel('Time (sec)');
% ------------------------------
- 演習: 例題プログラムを実行してみよう
まず実行してみて,このプログラムの内容をよく理解してください。
さて,モデルの次数はどれぐらいが良いでしょうか?- 予測誤差に周期性が認められるということは?
- モデル次数をかえてみてください。
- スペクトルが3つのピークを持つようにするためにはAR次数は最低いくつ必要でしょうか?
- 鋭いスペクトルをもつ時系列には,Burg法のほうが良い?
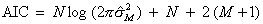
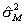 は,予測誤差の分散(推定値)である。
は,予測誤差の分散(推定値)である。